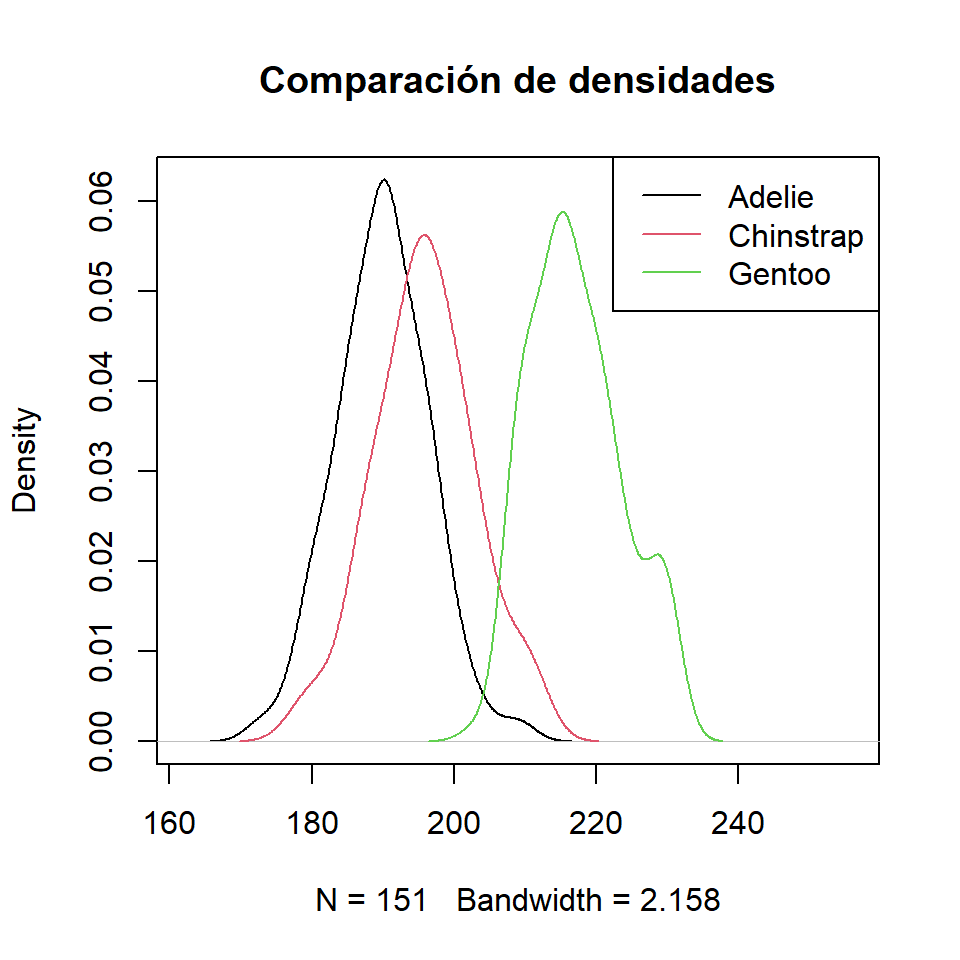
La función hist utiliza el método de Sturges por defecto para determinar el número de intervalos de clase del histograma. La selección es muy importante, ya que muchas clases incrementarán la variabilidad y muy pocas agruparán los datos demasiado.
El argumento breaks
El argumento breaks controla el número de barras o clases del histograma. El valor por defecto es breaks = "Sturges".
El método de Sturges (por defecto)
El método por defecto es el más recomendado en la mayoría de los casos.
# Datos de muestra
set.seed(2)
x <- rnorm(2000)
# Histograma
hist(x,
main = "Sturges")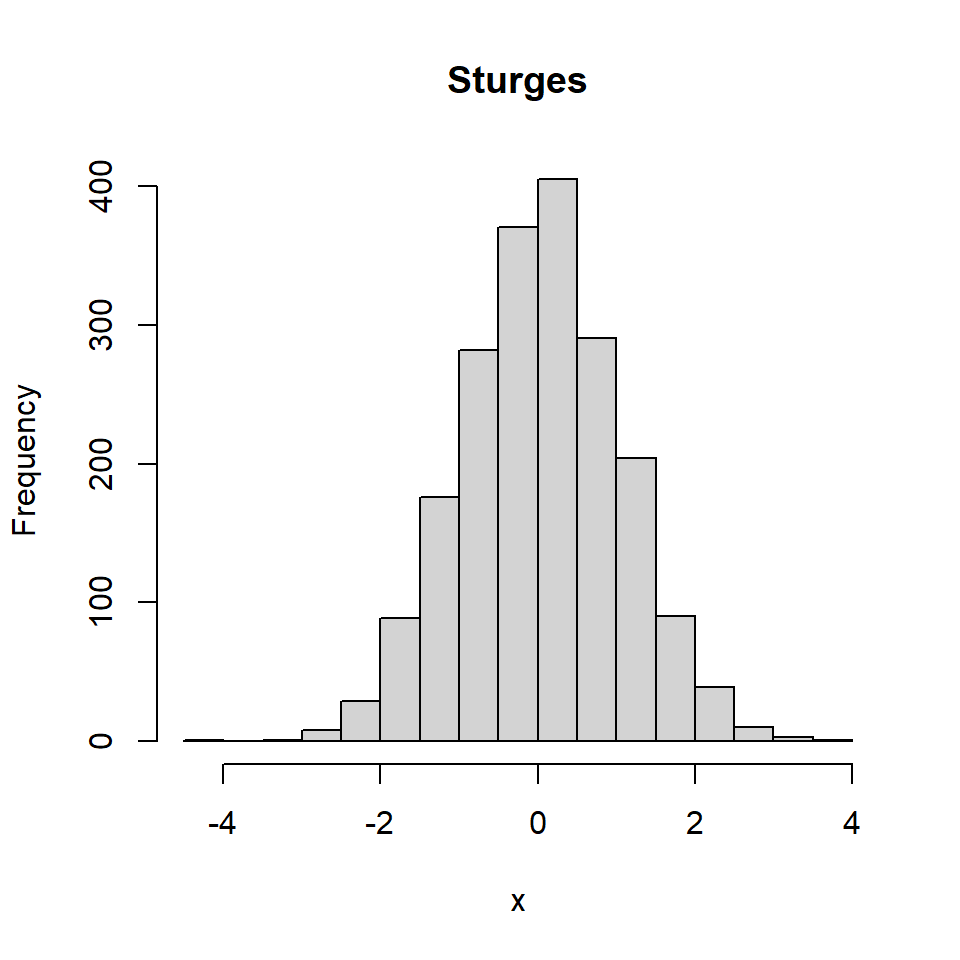
Muchas clases
Si especificas un número de clases manualmente intenta seleccionar un valor adecuado, que no agrupe los datos en exceso.
# Datos de muestra
set.seed(2)
x <- rnorm(2000)
# Histograma
hist(x, breaks = 80,
main = "Muchas clases")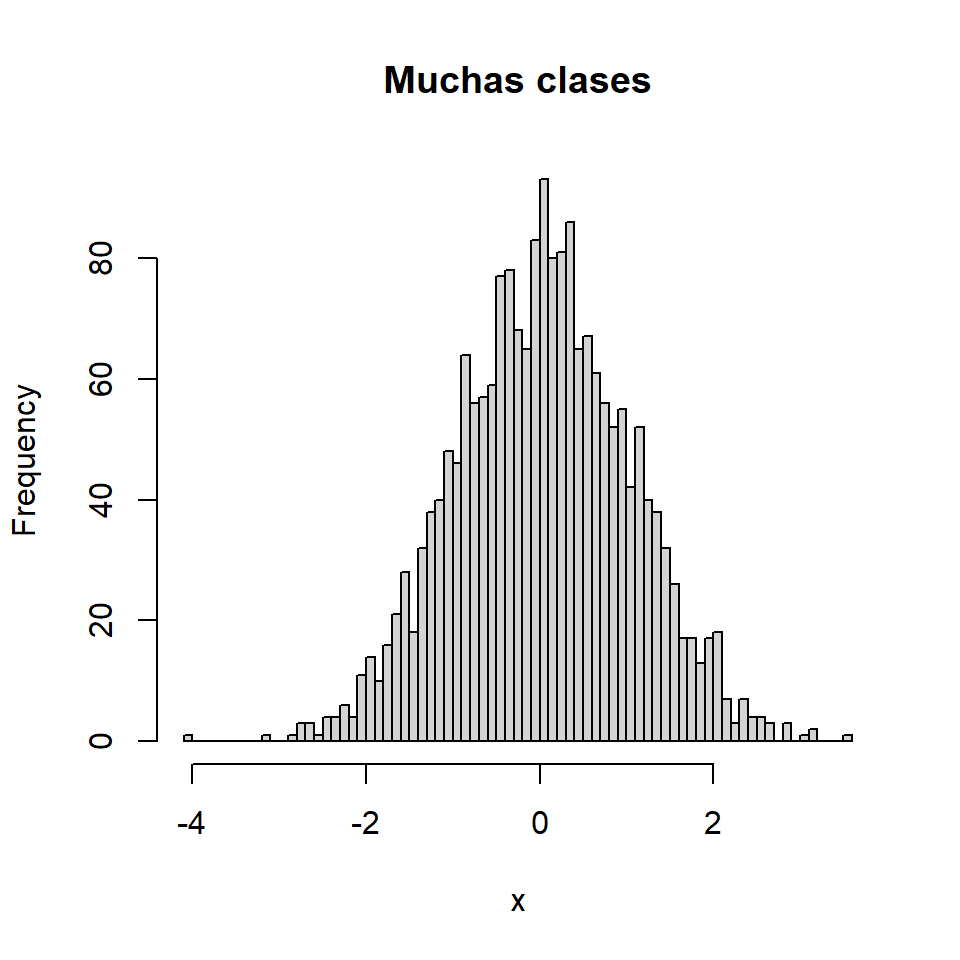
Pocas clases
El número de clases también puede ser demasiado pequeño en algunos escenarios.
# Datos de muestra
set.seed(2)
x <- rnorm(2000)
# Histograma
hist(x, breaks = 5,
main = "Pocas clases")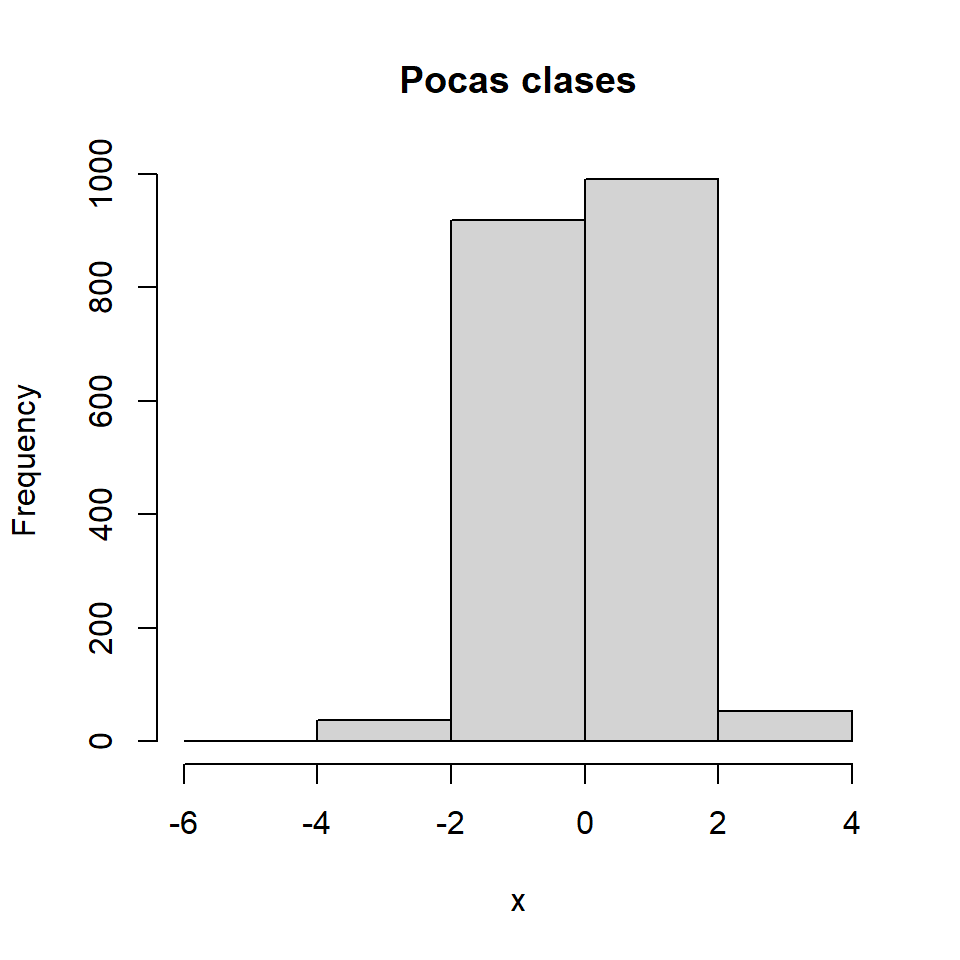
Método de Scott
Además del método de Sturges el argumento breaks también permite seleccionar el método de Scott.
# Datos de muestra
set.seed(2)
x <- rnorm(2000)
# Histograma
hist(x, breaks = "Scott",
main = "Scott")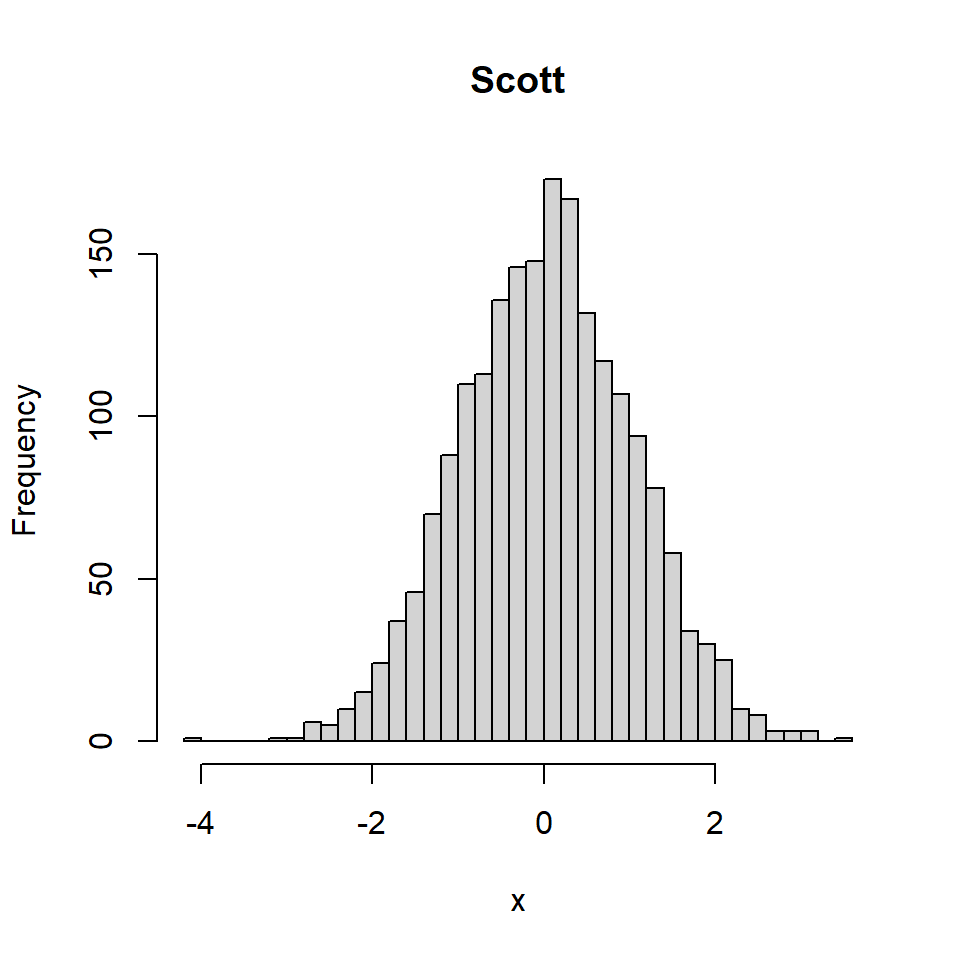
Método de Freedman-Diaconis (FD)
El algoritmo de Freedman-Diaconis se puede seleccionar pasando “Freedman-Diaconis” o “FD” al argumento.
# Datos de muestra
set.seed(2)
x <- rnorm(2000)
# Histograma
hist(x, breaks = "Freedman-Diaconis",
main = "Freedman-Diaconis")
hist(x, breaks = "FD", # Equivalentee
main = "Freedman-Diaconis") 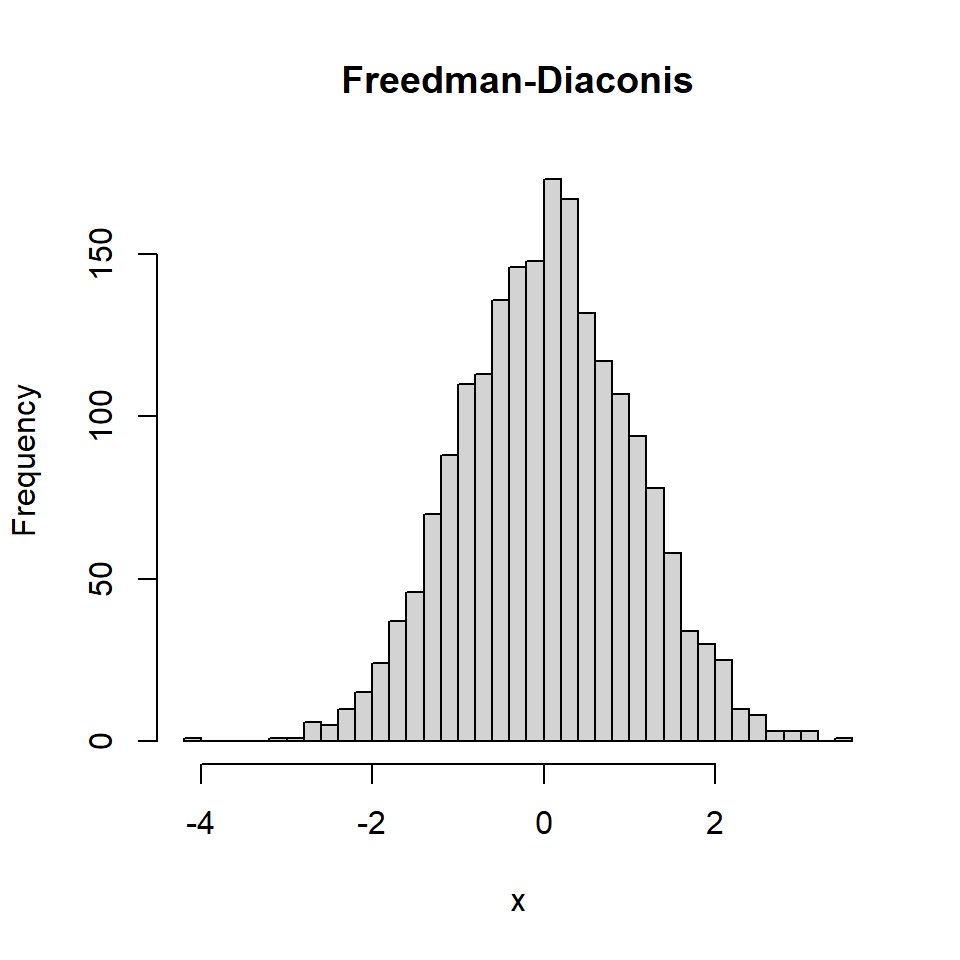
También puedes pasar un vector que devuelva el número de puntos de corte o una función para calcular el número de clases o los puntos de corte.
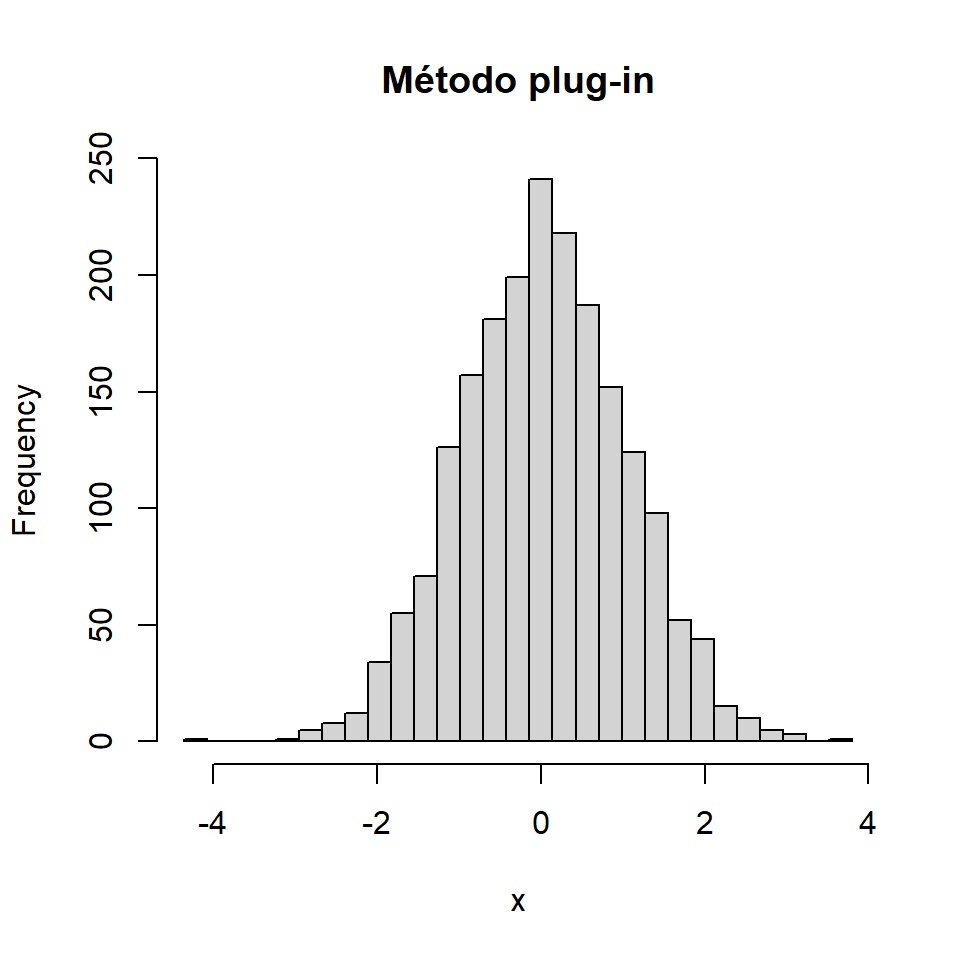
Método plug in
Una alternativa al método de Sturges o de seleccionar el número de clases a mano es utilizar el método plug-in para calcular la ventana óptima (Wand, 1995). Este método se implementa en KernSmooth y puedes utilizarlo como se muestra a continuación.
# Datos de muestra
set.seed(2)
x <- rnorm(2000)
# install.packages("KernSmooth")
library(KernSmooth)
# Ventana óptima
bin_width <- dpih(x)
# Número de clases
nbins <- seq(min(x) - bin_width,
max(x) + bin_width,
by = bin_width)
# Histograma
hist(x, breaks = nbins,
main = "Método plug-in")